Traditional transformer-based language models have a fundamental limitation: no matter how much context they process, that information never updates the model's long-term parameters. The knowledge stays trapped in the context window, lost forever once the conversation ends.
Nested Learning, introduced by Google Research at NeurIPS 2025, proposes a radical solution: what if neural networks could update their own weights during inference? What if every forward pass wasn't just computation, but also learning?
We've implemented the complete Nested Learning framework in PyTorch, making this cutting-edge research accessible and practical. Here's what we learned building it.
Key Innovation
Unlike traditional models where weights are frozen after training, Nested Learning enables "memory updates happen at inference time, not just during training" - creating systems of interconnected, multi-level learning problems optimized simultaneously.
The Architecture: Four Pillars of Self-Modifying Memory
The framework consists of four interlocking components, each solving a different aspect of test-time learning:
Associative Memory
The foundational building block using Hebbian and delta rule mechanisms for learnable key-value mappings.
Test-Time Learning Memory
DeltaRuleMemory and SelfModifyingMemory variants that adapt their weights during forward passes.
Continuum Memory System
Multi-frequency hierarchy where different levels update at different temporal rates.
Hope Transformer
Complete self-modifying sequence model combining all components into a unified architecture.
Associative Memory: The Learning Foundation
At the core of Nested Learning lies a beautifully simple idea: weight matrices that adapt through outer products. The update rule follows the classic Hebbian principle - "neurons that fire together, wire together":
W += lr * (v ⊗ k)
Where v is the value to store, k is the key, and lr is the learning rate.
This creates an associative memory that can store and retrieve key-value pairs, updating itself with each new association.
class AssociativeMemory(nn.Module):
def __init__(self, key_dim, value_dim):
super().__init__()
self.W = nn.Parameter(torch.zeros(value_dim, key_dim))
self.lr = nn.Parameter(torch.tensor(0.1))
def forward(self, key, value=None):
# Retrieval: simply multiply
retrieved = self.W @ key
# Learning: update weights if value provided
if value is not None:
with torch.no_grad():
self.W += self.lr * torch.outer(value, key)
return retrievedSelf-Modifying Memory: Learning the Learning Rate
The breakthrough insight of Self-Modifying Memory is that the learning rate itself should be learned.
Rather than using a fixed lr, the network predicts an adaptive learning rate based on how
"surprising" the input is:
class SelfModifyingMemory(nn.Module):
def forward(self, key, value):
# Predict what we expect
predicted = self.W @ key
# Measure surprise (prediction error)
surprise = torch.norm(value - predicted)
# Adaptive learning rate based on surprise
adaptive_lr = self.lr_network(surprise)
# Update more aggressively for surprising inputs
self.W += adaptive_lr * torch.outer(value - predicted, key)This creates a system that learns quickly from novel information while remaining stable on familiar patterns - exactly the behavior we want from a continuously learning system.
The Continuum Memory System: Time-Scale Hierarchy
Perhaps the most elegant component is the Continuum Memory System (CMS). Inspired by how biological memory operates at multiple time scales - from working memory to long-term consolidation - CMS implements a hierarchy of memories updating at different rates:
- Level 0 (Working Memory): Updates every single token - rapid, volatile
- Level 1: Updates every 2 tokens - short-term patterns
- Level 2: Updates every 4 tokens - medium-term context
- Level 3 (Long-term): Updates every 8 tokens - persistent knowledge
Each level acts as a filter, only consolidating information that remains relevant across its time window. The result is a natural hierarchy where transient details stay in fast memory while enduring patterns migrate to slower, more stable storage.
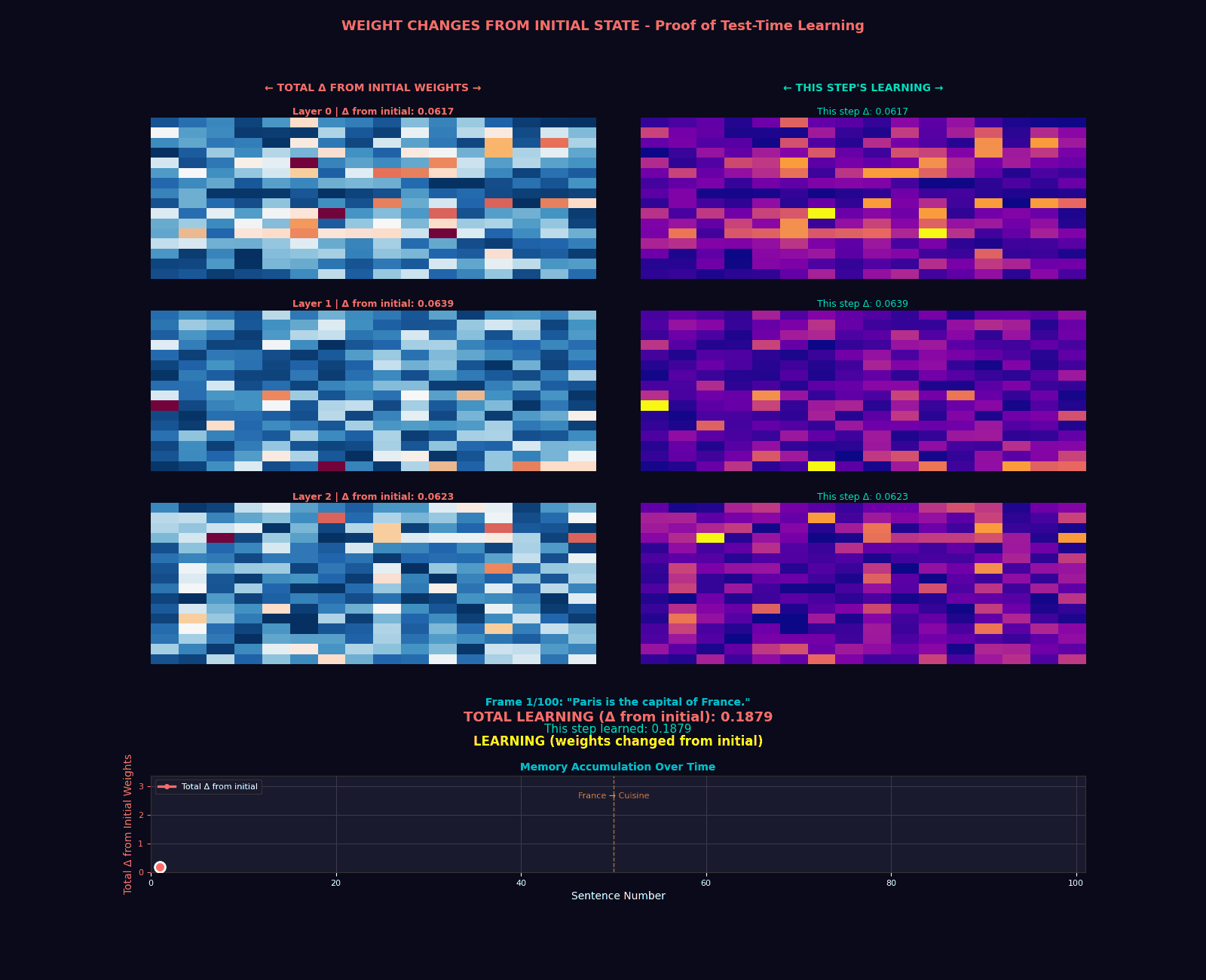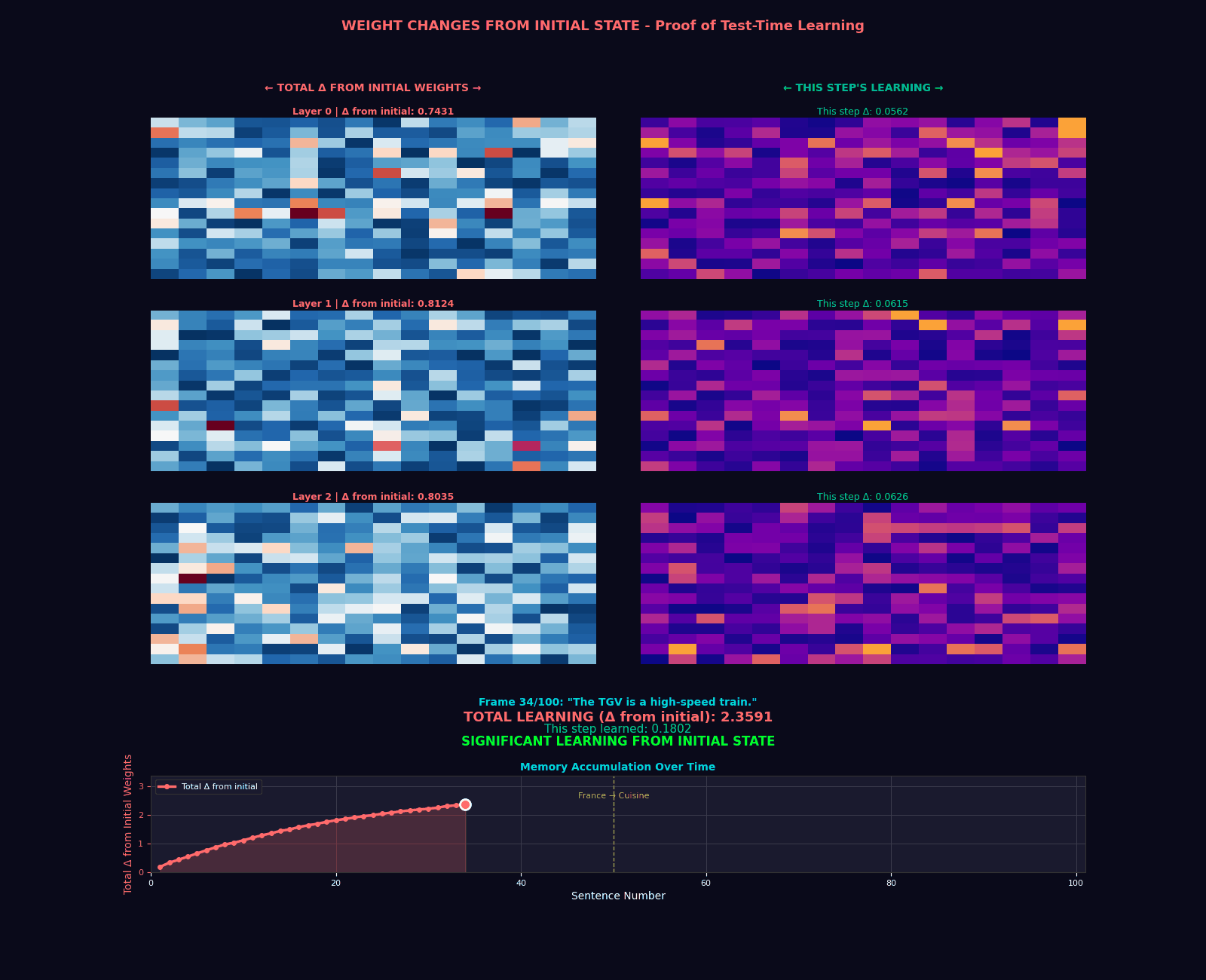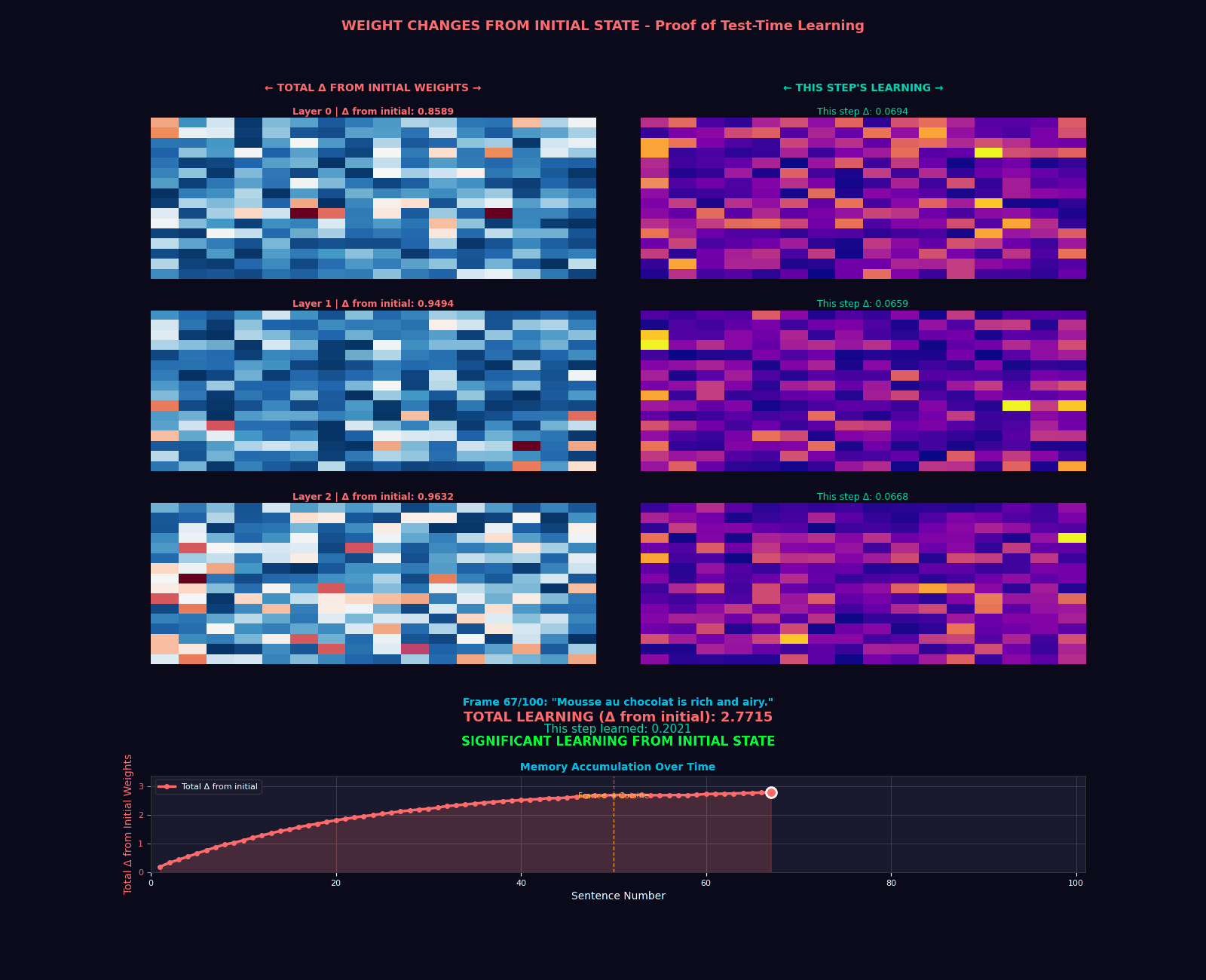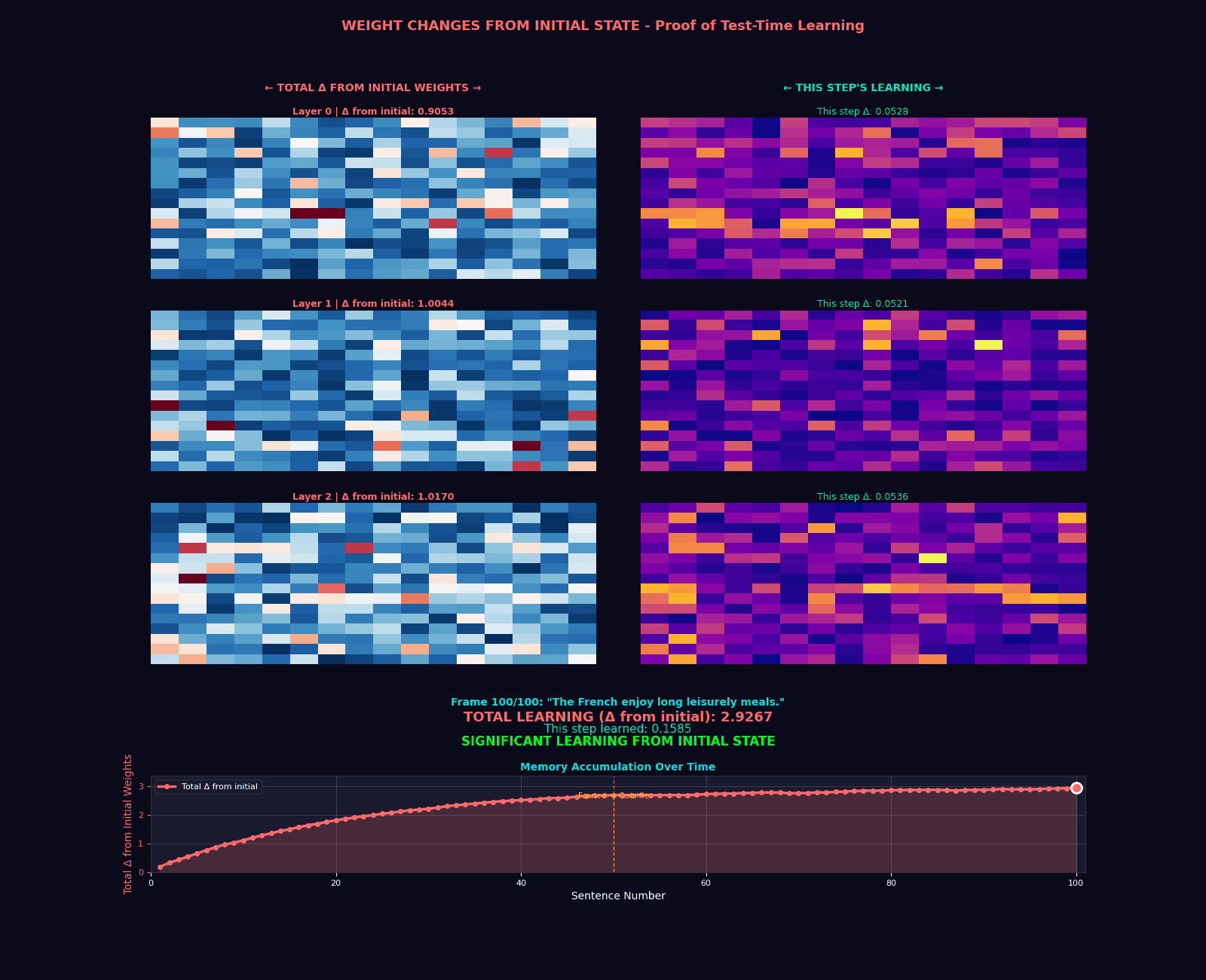
The Hope Transformer: Putting It All Together
The Hope Transformer integrates all these components into a complete sequence model. Each layer contains:
- Self-attention with causal masking
- Self-Modifying Memory for adaptive storage
- Continuum Memory System for multi-scale learning
- Persistent memory tokens that carry information across sequences
- Standard feedforward networks
The architecture enables something remarkable: a model that genuinely learns from each input it processes, continuously refining its internal representations based on experience.
Validation: Does Test-Time Learning Actually Work?
Extraordinary claims require extraordinary evidence. Our implementation includes a comprehensive test suite that validates five critical properties:
- Memory State Updates: Verify that memory parameters actually change during inference
- Repetition Learning: Confirm that repeated patterns are learned and retrieved more accurately
- In-Context Association: Test that novel key-value pairs presented in context can be retrieved
- Memory Ablation: Validate that disabling memory components degrades performance predictably
- Long-Range Persistence: Ensure that information persists across extended sequences
def test_memory_actually_updates():
model = HopeTransformer(...)
# Capture initial memory state
initial_state = model.memory.W.clone()
# Process sequence
model(test_sequence)
# Verify memory changed
assert not torch.equal(model.memory.W, initial_state)
print("Memory successfully updated during inference!")Why This Matters for Self-Improving AI
Nested Learning represents a paradigm shift in how we think about AI systems. Traditional machine learning separates training (where learning happens) from inference (where learning stops). This creates brittle systems that can't adapt to new situations without expensive retraining.
Self-modifying memory dissolves this boundary. Every interaction becomes an opportunity for improvement. Every novel input refines the model's understanding. This is the foundation for truly autonomous, self-improving AI - systems that get smarter through use, not just through periodic updates.
"The goal is not just models that perform well, but models that continuously improve their performance through experience - without human intervention."
At Flaw AI, we're building on these principles to create enterprise AI agents that don't just execute tasks but genuinely learn from every interaction. Agents that identify their own weaknesses, generate improvements, and deploy them autonomously. The Nested Learning framework is one piece of that larger vision.
Try It Yourself
Our complete implementation is open source and available on GitHub. It includes:
- Full PyTorch implementation of all components
- Comprehensive test suite validating memory behavior
- Training scripts with Wikipedia dataset integration
- Visualization tools for analyzing memory dynamics
- Weights & Biases logging for experiment tracking
Building Self-Improving AI for Your Enterprise?
We're applying these research breakthroughs to create production-ready AI agents that continuously improve without manual intervention.
Request a Demo